
티스토리 뷰
파이썬 기반 공공데이터 API 분석모델 구축
2. 데이터 수집 프로그램
- Beautiful Soup
- Beautiful Soup 정의
- Beautiful Soup 설정하기
- 벅스뮤직 예제
- 위키피디아 예제
- 셀레니움과 크롬드라이버
- 셀레니움과 크롬드라이버 설정하기
- 네이버 영화 예제
- 네이버 자동 로그인 예제
- 텍스트 마이닝
- 데이터 다운로드
- 삼성 2018 산업보고서 예제
Beautiful Soup
Beautiful Soup 정의
Beautiful Soup은 HTML과 XML 문서를 구문 분석하기 위한 파이썬 패키지입니다. HTML에서 데이터를 추출하는 데 사용할 수 있는 구문 분석된 페이지에 대한 구문 분석 트리를 만듭니다. 이것은 웹 스크래핑에 유용합니다.[위키백과]
Beautiful Soup 설정하기
pypi.org/project/로 접속합니다.
Beautiful Soup을 검색한다.beautifulsoup4 <버전> 을 선택합니다.
이 예제에서는 PIP 로 패키지를 설치하는 학습이 필요합니다.
패키지는 특정 기능을 수행하기 위한 함수들을 모아놓은 라이브러리(모듈)입니다.
PIP란 패키지 소프트웨어를 설치, 관리하는 시스템입니다.
추가하는 패키지는 다음과 같습니다.
pip install beautifulsoup4
pip install lxml
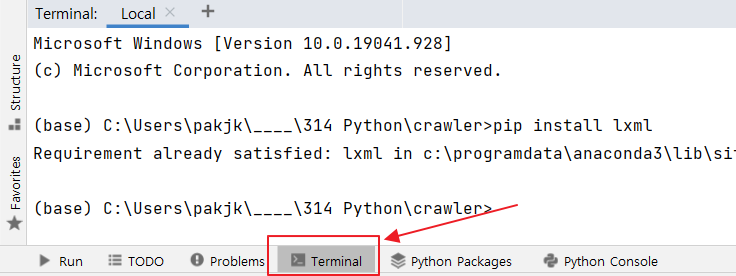
을 카피해서 <그림 1> 처럼 파이참 터미널에 붙여넣습니다.
벅스뮤직 예제
스크래핑할 주소는 ('https://music.bugs.co.kr/chart/track/realtime/total?chartdate=20181124&charthour=10music.bugs.co.kr/chart/track/day/total?chartdate=20210505') 입니다.
위키피디아 예제
스크래핑할 주소는 (http://dh.aks.ac.kr/Encyves/wiki/index.php/%EC%A1%B0%EC%84%A0_%EC%84%B8%EC%A2%85 ) 입니다. 스크랩핑하는 모듈을 작성합니다.
이 예제에서는 다음과 같은 선행 지식이 필요합니다. 이 문법을 CSS 셀렉터라고 합니다.(각주1)
- a.get('href') 태그 a 에서 href 속성의 값(하이퍼링크 url) 추출하기
- soup.title.name title 태그의 이름 title 추출하기
- soup.title.string title 태그의 문자값 추출하기
- soup.['class'] 클래스 추출
- soup.find(id = 'link') 아이디가 link 인 태그와 값 추출
(각주1) 출처 (www.w3schools.com/cssref/css_selectors.asp)
셀레니움과 크롬 드라이버
셀레니움 설정하기
추가하는 패키지는 다음과 같습니다. pip install selenium
conda install webdriver_manager : webdriver_manager 는 크롬 브라우저 버전이 업데이트 되면, 그에 맞는 크롬 드라이버를 자동으로 다운로드 해주는 라이브러리입니다.
크롬드라이버 설정하기
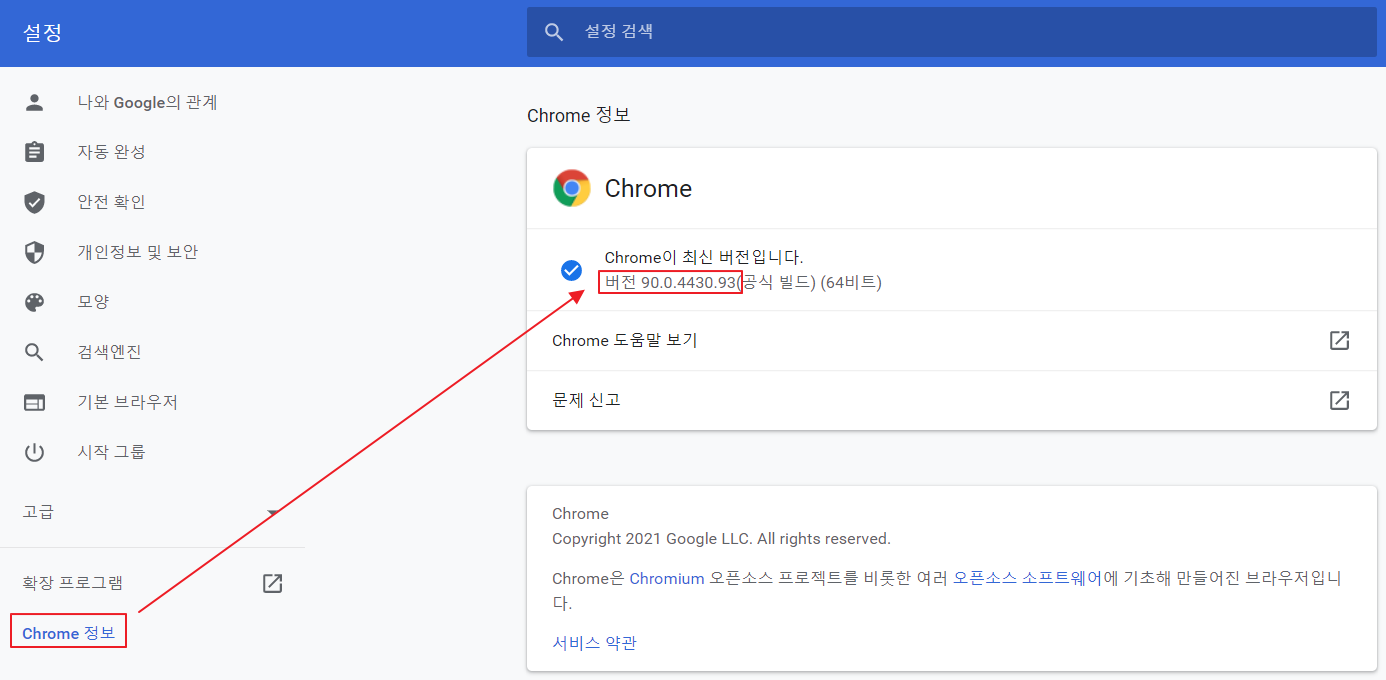
크롬 브라우저 우측 상단에 세로 점3개을 클릭 후 설정탭을 선택합니다. 좌측 Chrome 정보를 클릭합니다. <그림2>와 같이 크롬 버전을 확인합니다. chromedriver.chromium.org/downloads 에 접속합니다.
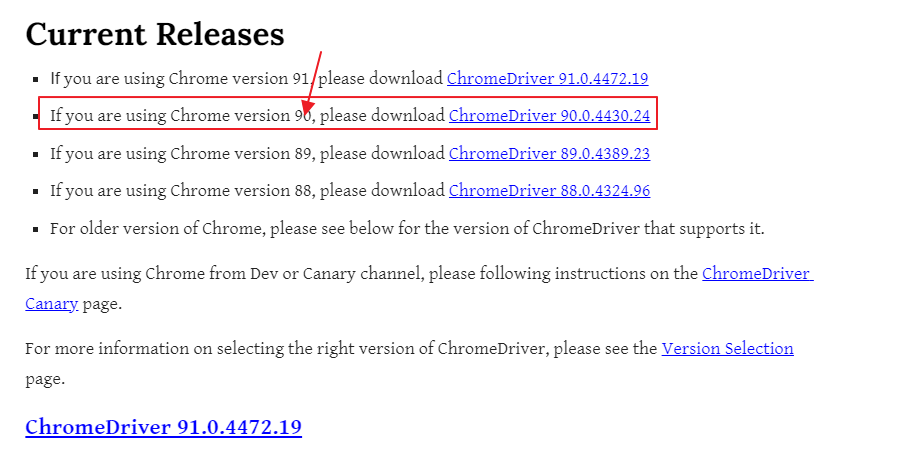
버전과 일치하는 드라이버를 <그림3> 처럼 선택한 후 본인 OS 와 맞춰서 다운받습니다.
다운받은 드라이버를 C:/Program Files/Google/Chrome 에 저장합니다.
해당 프로젝트의 경로를 카피해서, 작업 중인 모듈에 입력합니다.
다음 영화 예제(https://movie.daum.net/main)
이 예제에서는 requests 라이브러리를 사용합니다.
파이썬용 HTTP 라이브러리 입니다. HTTP, HTTPS 웹 사이트에 요청하기 위해 자주 사용하는 라이브러리이며, 크롤링 과정에서 웹의 소스코드를 가져와 파싱하는 경우에 주로 사용하게 됩니다.
그리고 html parser 에 대한 지식이 필요합니다.
[참고사이트]( docs.python.org/ko/3/library/html.parser.html)
그리고, List Comprehension을 사용한 for 문에 대한 내용은 다음과 같습니다.
a = [1,2,3,4]
result = [ i * 3 for i in a if i % 2 == 0 ]
print(result)
[6, 12]
네이버 자동 로그인
텍스트 마이닝
텍스트 마이닝은 비정형 텍스트에서 패턴, 관계 등을 분석하여 의미있는 정보를 도출해내는 데이터 마이닝 기법입니다.[참고사이트](itwiki.kr/w/%ED%85%8D%EC%8A%A4%ED%8A%B8_%EB%A7%88%EC%9D%B4%EB%8B%9D)
삼성 2018 산업보고서 텍스트 마이닝
이 예제에서는 로컬에 데이터를 다운로드 해야 합니다.
이 폴더에는 워드클라우드를 위한 폰트와 텍스트 마이닝 대상 파일, 제거할 노이즈 단어목록 파일을 포함하고 있습니다.
추가할 패키지는 KoNLPy 이다. 해당 패키지에 대한 홈페이지는 (konlpy.org/ko/v0.5.2/install/#) 입니다.
KoNLPy는 한국어 정보 전처리에 사용되는 파이썬 패키지다. 자연어처리(NLP)에서 형태소를 분리(형태소 단위 토크나이징)하는 데이터 전처리작업에서 많이 사용됩니다. KoNLPy 사이트는 설정하는 과정이 많이 생략되어 있어 이 블로그( https://ebbnflow.tistory.com/143)를 참조하는 것이 유용합니다.
추가로 NLTK (www.nltk.org/data.html) 에 관한 지식이 필요합니다. NLTK는 자연어 처리를 위한 파이썬 패키지입니다. 설정하는 과정은 이 블로그 (wikidocs.net/22488) 를 통해 참조하는 것이 유용합니다.
<참고자료>
'5. 파이썬' 카테고리의 다른 글
| 머신러닝/--/마드리드/ 타이타닉 (0) | 2021.08.03 |
|---|---|
| (마드리드) 파이썬> Flask requirements.txt (0) | 2021.07.30 |
| 파이썬 기반 공공데이터 API 분석모델 구축 1. 빅데이터 플랫폼 구축 (0) | 2021.05.07 |
| 파이썬/--/하이파/ 플라스크, 리액트 기반 주가예측 API stock.py (0) | 2020.12.01 |
| 파이썬/머신러닝/2020-10-29/ 주식거래 AI 추천서비스 (0) | 2020.10.29 |
- Total
- Today
- Yesterday
- Java
- SpringBoot
- Django
- KAFKA
- Oracle
- AWS
- Algorithm
- SQLAlchemy
- COLAB
- docker
- mariadb
- Python
- intellij
- FLASK
- JUnit
- React
- Mlearn
- nodejs
- jQuery
- tensorflow
- Git
- Eclipse
- Mongo
- vscode
- terms
- maven
- springMVC
- JPA
- database
- ERD
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |