
티스토리 뷰
|
1
|
!pip install transformers
|
cs |
|
1
2
3
4
5
6
7
8
9
|
import tensorflow as tf
import numpy as np
import pandas as pd
from transformers import *
import json
import numpy as np
import pandas as pd
from tqdm import tqdm
import os
|
cs |
|
1
2
|
# 네이버 영화 감성분석 데이터 다운로드
!git clone https://github.com/e9t/nsmc.git
|
cs |

|
1
|
os.listdir('nsmc')
|
cs |

|
1
2
3
4
|
# 딥러닝 훈련에 사용 할 train 데이터와 test 데이터를 pandas dataframe 형식으로 불러옵니다.
train = pd.read_table("nsmc/"+"ratings_train.txt")
test = pd.read_table("nsmc/"+"ratings_test.txt")
|
cs |
|
1
|
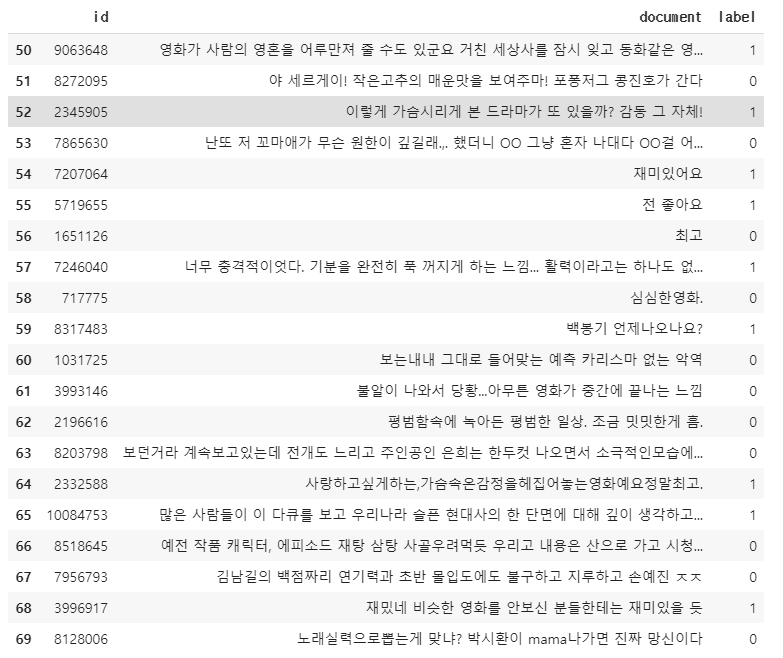
train[50:70]
|
cs |
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
|
import logging
import os
import unicodedata
from shutil import copyfile
from transformers import PreTrainedTokenizer
logger = logging.getLogger(__name__)
VOCAB_FILES_NAMES = {"vocab_file": "tokenizer_78b3253a26.model",
"vocab_txt": "vocab.txt"}
PRETRAINED_VOCAB_FILES_MAP = {
"vocab_file": {
"monologg/kobert": "https://s3.amazonaws.com/models.huggingface.co/bert/monologg/kobert/tokenizer_78b3253a26.model",
"monologg/kobert-lm": "https://s3.amazonaws.com/models.huggingface.co/bert/monologg/kobert-lm/tokenizer_78b3253a26.model",
"monologg/distilkobert": "https://s3.amazonaws.com/models.huggingface.co/bert/monologg/distilkobert/tokenizer_78b3253a26.model"
},
"vocab_txt": {
"monologg/kobert": "https://s3.amazonaws.com/models.huggingface.co/bert/monologg/kobert/vocab.txt",
"monologg/kobert-lm": "https://s3.amazonaws.com/models.huggingface.co/bert/monologg/kobert-lm/vocab.txt",
"monologg/distilkobert": "https://s3.amazonaws.com/models.huggingface.co/bert/monologg/distilkobert/vocab.txt"
}
}
PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES = {
"monologg/kobert": 512,
"monologg/kobert-lm": 512,
"monologg/distilkobert": 512
}
PRETRAINED_INIT_CONFIGURATION = {
"monologg/kobert": {"do_lower_case": False},
"monologg/kobert-lm": {"do_lower_case": False},
"monologg/distilkobert": {"do_lower_case": False}
}
SPIECE_UNDERLINE = u'▁'
class KoBertTokenizer(PreTrainedTokenizer):
"""
SentencePiece based tokenizer. Peculiarities:
- requires `SentencePiece <https://github.com/google/sentencepiece>`_
"""
vocab_files_names = VOCAB_FILES_NAMES
pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
pretrained_init_configuration = PRETRAINED_INIT_CONFIGURATION
max_model_input_sizes = PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
def __init__(
self,
vocab_file,
vocab_txt,
do_lower_case=False,
remove_space=True,
keep_accents=False,
unk_token="[UNK]",
sep_token="[SEP]",
pad_token="[PAD]",
cls_token="[CLS]",
mask_token="[MASK]",
**kwargs):
super().__init__(
unk_token=unk_token,
sep_token=sep_token,
pad_token=pad_token,
cls_token=cls_token,
mask_token=mask_token,
**kwargs
)
# Build vocab
self.token2idx = dict()
self.idx2token = []
with open(vocab_txt, 'r', encoding='utf-8') as f:
for idx, token in enumerate(f):
token = token.strip()
self.token2idx[token] = idx
self.idx2token.append(token)
self.max_len_single_sentence = self.max_len - 2 # take into account special tokens
self.max_len_sentences_pair = self.max_len - 3 # take into account special tokens
try:
import sentencepiece as spm
except ImportError:
logger.warning("You need to install SentencePiece to use KoBertTokenizer: https://github.com/google/sentencepiece"
"pip install sentencepiece")
self.do_lower_case = do_lower_case
self.remove_space = remove_space
self.keep_accents = keep_accents
self.vocab_file = vocab_file
self.vocab_txt = vocab_txt
self.sp_model = spm.SentencePieceProcessor()
self.sp_model.Load(vocab_file)
@property
def vocab_size(self):
return len(self.idx2token)
def __getstate__(self):
state = self.__dict__.copy()
state["sp_model"] = None
return state
def __setstate__(self, d):
self.__dict__ = d
try:
import sentencepiece as spm
except ImportError:
logger.warning("You need to install SentencePiece to use KoBertTokenizer: https://github.com/google/sentencepiece"
"pip install sentencepiece")
self.sp_model = spm.SentencePieceProcessor()
self.sp_model.Load(self.vocab_file)
def preprocess_text(self, inputs):
if self.remove_space:
outputs = " ".join(inputs.strip().split())
else:
outputs = inputs
outputs = outputs.replace("``", '"').replace("''", '"')
if not self.keep_accents:
outputs = unicodedata.normalize('NFKD', outputs)
outputs = "".join([c for c in outputs if not unicodedata.combining(c)])
if self.do_lower_case:
outputs = outputs.lower()
return outputs
def _tokenize(self, text, return_unicode=True, sample=False):
""" Tokenize a string. """
text = self.preprocess_text(text)
if not sample:
pieces = self.sp_model.EncodeAsPieces(text)
else:
pieces = self.sp_model.SampleEncodeAsPieces(text, 64, 0.1)
new_pieces = []
for piece in pieces:
if len(piece) > 1 and piece[-1] == str(",") and piece[-2].isdigit():
cur_pieces = self.sp_model.EncodeAsPieces(piece[:-1].replace(SPIECE_UNDERLINE, ""))
if piece[0] != SPIECE_UNDERLINE and cur_pieces[0][0] == SPIECE_UNDERLINE:
if len(cur_pieces[0]) == 1:
cur_pieces = cur_pieces[1:]
else:
cur_pieces[0] = cur_pieces[0][1:]
cur_pieces.append(piece[-1])
new_pieces.extend(cur_pieces)
else:
new_pieces.append(piece)
return new_pieces
def _convert_token_to_id(self, token):
""" Converts a token (str/unicode) in an id using the vocab. """
return self.token2idx.get(token, self.token2idx[self.unk_token])
def _convert_id_to_token(self, index, return_unicode=True):
"""Converts an index (integer) in a token (string/unicode) using the vocab."""
return self.idx2token[index]
def convert_tokens_to_string(self, tokens):
"""Converts a sequence of tokens (strings for sub-words) in a single string."""
out_string = "".join(tokens).replace(SPIECE_UNDERLINE, " ").strip()
return out_string
def build_inputs_with_special_tokens(self, token_ids_0, token_ids_1=None):
"""
Build model inputs from a sequence or a pair of sequence for sequence classification tasks
by concatenating and adding special tokens.
A RoBERTa sequence has the following format:
single sequence: [CLS] X [SEP]
pair of sequences: [CLS] A [SEP] B [SEP]
"""
if token_ids_1 is None:
return [self.cls_token_id] + token_ids_0 + [self.sep_token_id]
cls = [self.cls_token_id]
sep = [self.sep_token_id]
return cls + token_ids_0 + sep + token_ids_1 + sep
def get_special_tokens_mask(self, token_ids_0, token_ids_1=None, already_has_special_tokens=False):
"""
Retrieves sequence ids from a token list that has no special tokens added. This method is called when adding
special tokens using the tokenizer ``prepare_for_model`` or ``encode_plus`` methods.
Args:
token_ids_0: list of ids (must not contain special tokens)
token_ids_1: Optional list of ids (must not contain special tokens), necessary when fetching sequence ids
for sequence pairs
already_has_special_tokens: (default False) Set to True if the token list is already formated with
special tokens for the model
Returns:
A list of integers in the range [0, 1]: 0 for a special token, 1 for a sequence token.
"""
if already_has_special_tokens:
if token_ids_1 is not None:
raise ValueError(
"You should not supply a second sequence if the provided sequence of "
"ids is already formated with special tokens for the model."
)
return list(map(lambda x: 1 if x in [self.sep_token_id, self.cls_token_id] else 0, token_ids_0))
if token_ids_1 is not None:
return [1] + ([0] * len(token_ids_0)) + [1] + ([0] * len(token_ids_1)) + [1]
return [1] + ([0] * len(token_ids_0)) + [1]
def create_token_type_ids_from_sequences(self, token_ids_0, token_ids_1=None):
"""
Creates a mask from the two sequences passed to be used in a sequence-pair classification task.
A BERT sequence pair mask has the following format:
0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1
| first sequence | second sequence
if token_ids_1 is None, only returns the first portion of the mask (0's).
"""
sep = [self.sep_token_id]
cls = [self.cls_token_id]
if token_ids_1 is None:
return len(cls + token_ids_0 + sep) * [0]
return len(cls + token_ids_0 + sep) * [0] + len(token_ids_1 + sep) * [1]
def save_vocabulary(self, save_directory):
""" Save the sentencepiece vocabulary (copy original file) and special tokens file
to a directory.
"""
if not os.path.isdir(save_directory):
logger.error("Vocabulary path ({}) should be a directory".format(save_directory))
return
# 1. Save sentencepiece model
out_vocab_model = os.path.join(save_directory, VOCAB_FILES_NAMES["vocab_file"])
if os.path.abspath(self.vocab_file) != os.path.abspath(out_vocab_model):
copyfile(self.vocab_file, out_vocab_model)
# 2. Save vocab.txt
index = 0
out_vocab_txt = os.path.join(save_directory, VOCAB_FILES_NAMES["vocab_txt"])
with open(out_vocab_txt, "w", encoding="utf-8") as writer:
for token, token_index in sorted(self.token2idx.items(), key=lambda kv: kv[1]):
if index != token_index:
logger.warning(
"Saving vocabulary to {}: vocabulary indices are not consecutive."
" Please check that the vocabulary is not corrupted!".format(out_vocab_txt)
)
index = token_index
writer.write(token + "\n")
index += 1
return out_vocab_model, out_vocab_txt
|
cs |
|
1
2
|
# kobert 토크나이즈를 임포트합니다.
tokenizer = KoBertTokenizer.from_pretrained('monologg/kobert')
|
cs |

|
1
2
3
4
|
# 버트를 사용하기에 앞서 가장 기초에 속하는 tokenizer 사용 방법에 대해서 잠시 배워보도록 하겠습니다.
# tokenizer.encode => 문장을 버트 모델의 인풋 토큰값으로 바꿔줌
# tokenizer.tokenize => 문장을 토큰화
print(tokenizer.encode("보는내내 그대로 들어맞는 예측 카리스마 없는 악역"))
|
cs |
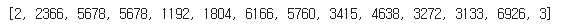
|
1
|
print(tokenizer.tokenize("보는내내 그대로 들어맞는 예측 카리스마 없는 악역"))
|
cs |
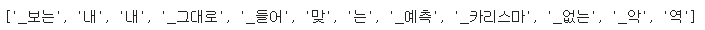
|
1
|
print(tokenizer.tokenize("전율을 일으키는 영화. 다시 보고싶은 영화"))
|
cs |

|
1
|
print(tokenizer.encode("전율을 일으키는 영화. 다시 보고싶은 영화"))
|
cs |
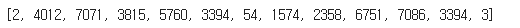
|
1
|
print(tokenizer.encode("전율을 일으키는 영화. 다시 보고싶은 영화", max_length=64, pad_to_max_length=True))
|
cs |
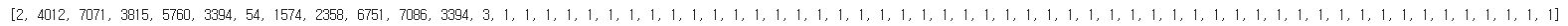
|
1
2
|
# 세그멘트 인풋
print([0]*64)
|
cs |
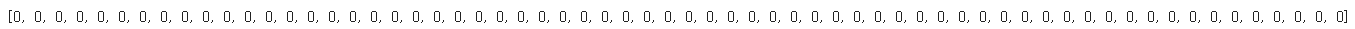
|
1
2
3
|
# 마스크 인풋
valid_num = len(tokenizer.encode("전율을 일으키는 영화. 다시 보고싶은 영화"))
print(valid_num * [1] + (64 - valid_num) * [0])
|
cs |

|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
|
def convert_data(data_df):
global tokenizer
SEQ_LEN = 64 #SEQ_LEN : 버트에 들어갈 인풋의 길이
tokens, masks, segments, targets = [], [], [], []
for i in tqdm(range(len(data_df))):
# token : 문장을 토큰화함
token = tokenizer.encode(data_df[DATA_COLUMN][i], max_length=SEQ_LEN, pad_to_max_length=True)
# 마스크는 토큰화한 문장에서 패딩이 아닌 부분은 1, 패딩인 부분은 0으로 통일
num_zeros = token.count(0)
mask = [1]*(SEQ_LEN-num_zeros) + [0]*num_zeros
# 문장의 전후관계를 구분해주는 세그먼트는 문장이 1개밖에 없으므로 모두 0
segment = [0]*SEQ_LEN
# 버트 인풋으로 들어가는 token, mask, segment를 tokens, segments에 각각 저장
tokens.append(token)
masks.append(mask)
segments.append(segment)
# 정답(긍정 : 1 부정 0)을 targets 변수에 저장해 줌
targets.append(data_df[LABEL_COLUMN][i])
# tokens, masks, segments, 정답 변수 targets를 numpy array로 지정
tokens = np.array(tokens)
masks = np.array(masks)
segments = np.array(segments)
targets = np.array(targets)
return [tokens, masks, segments], targets
# 위에 정의한 convert_data 함수를 불러오는 함수를 정의
def load_data(pandas_dataframe):
data_df = pandas_dataframe
data_df[DATA_COLUMN] = data_df[DATA_COLUMN].astype(str)
data_df[LABEL_COLUMN] = data_df[LABEL_COLUMN].astype(int)
data_x, data_y = convert_data(data_df)
return data_x, data_y
SEQ_LEN = 64
BATCH_SIZE = 32
# 긍부정 문장을 포함하고 있는 칼럼
DATA_COLUMN = "document"
# 긍정인지 부정인지를 (1=긍정,0=부정) 포함하고 있는 칼럼
LABEL_COLUMN = "label"
# train 데이터를 버트 인풋에 맞게 변환
train_x, train_y = load_data(train)
|
cs |
100%|██████████| 150000/150000 [00:28<00:00, 5242.74it/s]
|
1
2
|
# 훈련 성능을 검증한 test 데이터를 버트 인풋에 맞게 변환
test_x, test_y = load_data(test)
|
cs |
100%|██████████| 50000/50000 [00:09<00:00, 5333.47it/s]
|
1
2
3
4
5
6
7
8
|
# 버트 훈련을 빠르게 하기 위해, TPU를 사용하도록 하겠습니다
model = TFBertModel.from_pretrained("monologg/kobert", from_pt=True)
# 토큰 인풋, 마스크 인풋, 세그먼트 인풋 정의
token_inputs = tf.keras.layers.Input((SEQ_LEN,), dtype=tf.int32, name='input_word_ids')
mask_inputs = tf.keras.layers.Input((SEQ_LEN,), dtype=tf.int32, name='input_masks')
segment_inputs = tf.keras.layers.Input((SEQ_LEN,), dtype=tf.int32, name='input_segment')
# 인풋이 [토큰, 마스크, 세그먼트]인 모델 정의
bert_outputs = model([token_inputs, mask_inputs, segment_inputs])
|
cs |

|
1
|
bert_outputs
|
cs |
(<tf.Tensor 'tf_bert_model/Identity:0' shape=(None, 64, 768) dtype=float32>,
<tf.Tensor 'tf_bert_model/Identity_1:0' shape=(None, 768) dtype=float32>)
|
1
|
bert_outputs = bert_outputs[1]
|
cs |
|
1
2
3
4
|
# Rectified Adam 옵티마이저 사용
import tensorflow_addons as tfa
# 총 batch size * 4 epoch = 2344 * 4
opt = tfa.optimizers.RectifiedAdam(lr=5.0e-5, total_steps = 2344*4, warmup_proportion=0.1, min_lr=1e-5, epsilon=1e-08, clipnorm=1.0)
|
cs |
|
1
2
3
4
|
sentiment_drop = tf.keras.layers.Dropout(0.5)(bert_outputs)
sentiment_first = tf.keras.layers.Dense(1, activation='sigmoid', kernel_initializer=tf.keras.initializers.TruncatedNormal(stddev=0.02))(sentiment_drop)
sentiment_model = tf.keras.Model([token_inputs, mask_inputs, segment_inputs], sentiment_first)
sentiment_model.compile(optimizer=opt, loss=tf.keras.losses.BinaryCrossentropy(), metrics = ['accuracy'])
|
cs |
|
1
|
sentiment_model.summary()
|
cs |

|
1
|
sentiment_model.fit(train_x, train_y, epochs=4, shuffle=True, batch_size=64, validation_data=(test_x, test_y))
|
cs |

여기서 TPU 4시간 학습 걸림...
'5. 파이썬' 카테고리의 다른 글
| 83536 코스피 Trader.py (0) | 2020.06.02 |
|---|---|
| [Telaviv] 뉴스 데이터 수집 (0) | 2020.05.30 |
| [Telaviv] 코랩(colab) 사용서 (0) | 2020.05.29 |
| 텐서플로/2020-05/텐진/ cifar10_model.ipynb (0) | 2020.05.29 |
| 83541. cat_and_dog.ipynb (0) | 2020.05.29 |
댓글
공지사항
최근에 올라온 글
최근에 달린 댓글
- Total
- Today
- Yesterday
링크
TAG
- maven
- Python
- Eclipse
- docker
- Mlearn
- nodejs
- Mongo
- Oracle
- Java
- terms
- Algorithm
- Git
- JUnit
- tensorflow
- SQLAlchemy
- ERD
- vscode
- JPA
- Django
- COLAB
- intellij
- React
- KAFKA
- jQuery
- FLASK
- database
- mariadb
- AWS
- springMVC
- SpringBoot
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
글 보관함